Notetaking with Markdown and EPUBs for E-Readers
Last updated: Nov 19, 2022
Hello World!
This is my first post on this blog and I’m excited to share one of my favorite workflows for learning, notetaking, and study/review.
I’m primarily a visual learner, and I remember things by reading them, thinking about them, and writing them down. Sometimes this sucks. It’s slow and time consuming, results in a ton of cluttered files, and of course not everything is available as written text. On the other hand, some advantages of being a notetaker are the ability to save and process information over a very long period of time. Notes that you took years ago can be brought up and can remind you of important facts or lessons you would never remember today. Additionally, notes can be shared with friends, colleagues, or students, which multiplies the value of the work put into taking the notes considerably.
Over the years I’ve used many different systems to take notes. Paper notebooks are actually great; writing by hand is good for memory and paper notebooks are durable in ways that digital notes are not. It’s harder to just throw them out; there’s no delete button. A downside though is they take up space and so, like almost everybody, I take mostly digital notes now. But I wanted to mention paper notebooks because, in a lot of ways, they represent the ideal of notetaking. Easy to produce, results in good retention, hard to destroy / lose.
During college, I switched to digital notes. In large part, this is because I was forced to by the professor of a Philosophy of Religion class who collected and graded our notes; my handwriting was illegible. It probably sounds maddening to be graded on your notes, but this was actually one of my favorite parts of the class. Finally we had insight into what professors were thinking when they read a book, what were they doing during that time, and how did they funnel from that experience of reading into their own independent work? Two things were incredibly important for this purpose: first, you need to distinguish between your thoughts and the author’s text, and second, any note taken must have a page number or source so that it can be cited when used in your own work. That’s basically it. From your notes, you need to know where your thoughts end and the author’s thoughts begin, and you need to be able to say where the author said the thing that you are going to talk about. Now, I don’t remember exactly the format that we used in this class, but it was something like this:
| Quote | Commentary | Page |
|---|---|---|
| “Foo is bar is baz” | Is foo really always baz though? | 29 |
This separates out each of the concerns; knowing what was said and intended by the author, knowing where they said it, and knowing how you feel about it, what you think about it, or how you connect it to other things you know about.
In grad school, I continued this pattern, sort of. As I started to weave together a 200-300 page document, along with articles and presentations along the way, it became much more important to have a global search and to be able to go from the inkling of an idea on the tip of your tongue to the exact location where you took notes on it to make sure that what you thought you remembered was actually what the author said. Originally I made huge files and compiled all of the notes needed for a chapter in them. These would often be 80-100 sparse pages of quotes and thoughts, so I started to call them “quote dumps” until I learned about the concept of a repository from some exposure to coding. And so I started to call these large files “repositories” in the hopes that they would be more orderly and proper with a fancier title. It looked something like this:

I mostly rejected closed-source note platforms like Evernote and Microsoft OneNote. I didn’t like the idea of an aging filetype, or my documents stuck behind a membership fee; I wanted something I could look at twenty or thirty years later and have roughly the same experience as today, so I was pretty much stuck with text files, rich text, and other simple things that I knew how to use. I didn’t know much about Markdown at the time. In the end it worked; I was able to find the stuff I was looking for, write my dissertation, and complete the degree. But looking back, there were a lot of things I could’ve really done better, and that brings us to today.
In a CS program, tests are a lot more important than they were in the humanities. Rather than building an index of a source text and plugging it into commentary for use in writing, I’m using notes to wrangle large amounts of facts and theory into something that can be reconsumed multiple times before a test. In short, cramming is kind of important. Additionally, since review is more important than looking things up at time of use, the reading experience is more important. It’s painful to read through pages of notes on a computer, or even an iPad in my opinion. So as a result, I started using E-Readers extensively in my review process and I’m going to explain how I write, convert, and consume EPUB notes on my E-reader.
Write in Markdown
For programmers, Markdown is more or less the lingua franca of documentation. Probably the majority of Readme files, which explain the contents and usage of software projects, are written in Markdown. It’s easy to use, can stay simple, or become relatively complex, has support for mathematical symbols in its extended forms, and is generally just the simplest interface you can use to write long-term machine-parsable docs by hand. What makes it so appealing also is that it’s very readable by humans in its original form too. Using only headers, lists, and quote blocks, which are very easy to interpret by the human eye in a Markdown file, you can put together a fully complete article. This page, for example, is written in Markdown using only the most basic elements. Writing in Markdown, it’s easy to see the formatted result using something like VS Code or even just a Markdown extension in your browser. When editing via VS Code, the experience looks something like this:
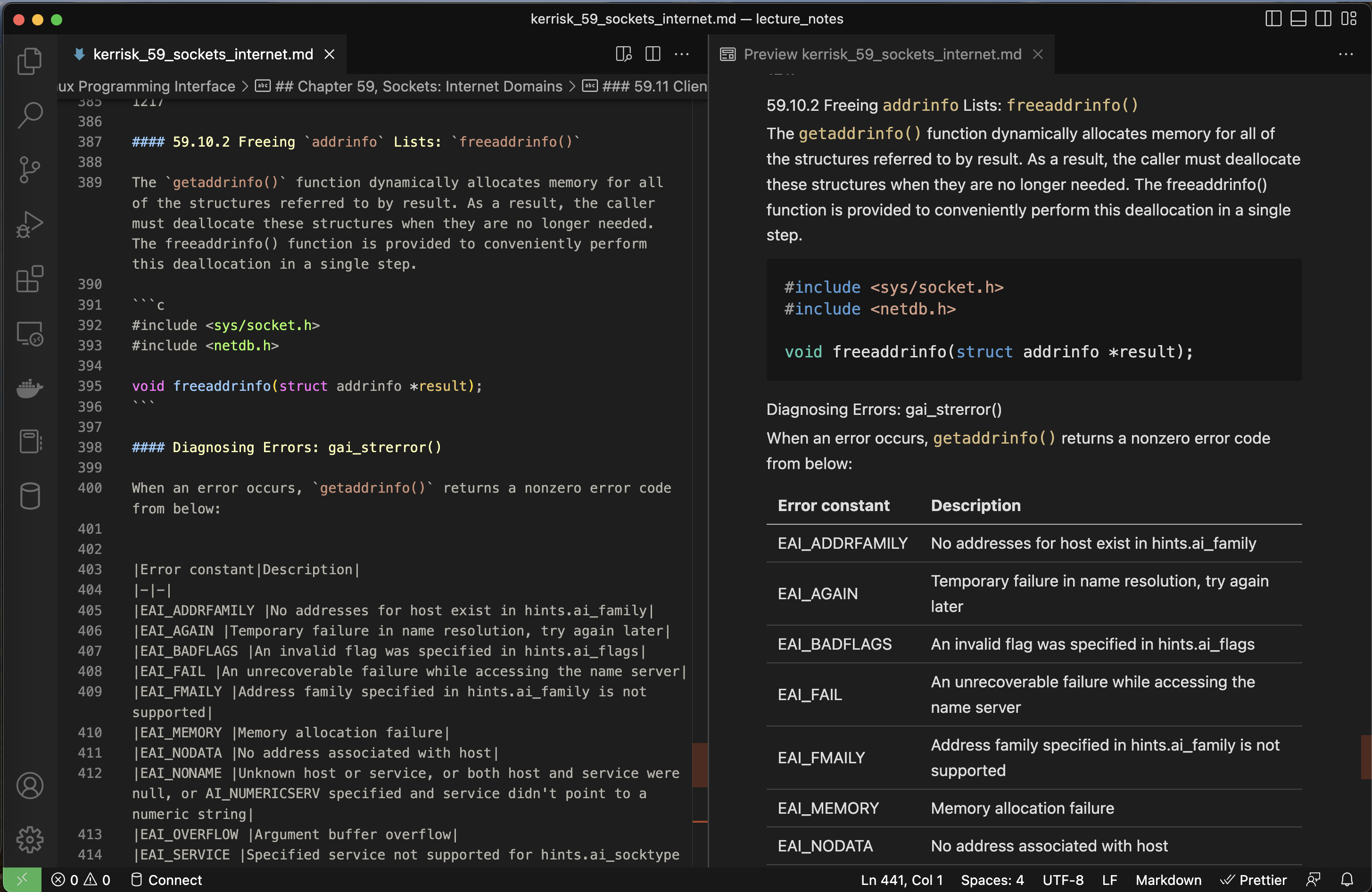
So for all of my CS notes, I use Markdown and keep them in directories based on the source or book that they’re from. Each file is named after the primary author’s last name, a recognizable part of the title, and the chapter. This makes searching across folders using something like ripgrep or even just the built-in Spotlight search in macOS super easy. At the end of a course that involves a lot of reading, this could result in a folder something like below:
.
├── elmasri_database_ch_01.md
├── elmasri_database_ch_02.md
├── elmasri_database_ch_03.md
├── elmasri_database_ch_04.md
├── elmasri_database_ch_05.md
├── elmasri_database_ch_06.md
├── elmasri_database_ch_07.md
├── elmasri_database_ch_08.md
├── elmasri_database_ch_09.md
├── elmasri_database_ch_14.md
├── elmasri_database_ch_15.md
├── elmasri_database_ch_16.md
└── elmasri_database_ch_17.md
Export to EPUB
Dang! That’s a lot of notes to review before the final test. I want to do that on the bus on my way to work, or on my couch sipping a cup of tea, not in front of my computer where my eyes will dry out and my back will start aching.
It’s time to convert these to EPUB files so they can be read on an E-Reader (or a smartphone). I use a super short Python script and the Pandoc library to mass export these for my Kobo E-Reader.
Set up requirements.txt as below.
pandoc==2.1
plumbum==1.7.2
ply==3.11
Install the dependencies in a virtual environment using pip
python3 -m venv venv
pip3 install -r requirements.txt
source venv/bin/activate
Create an export.py script file:
from os import getcwd, listdir
import pathlib
import pandoc
pathlib.Path("epub").mkdir(parents=True, exist_ok=True)
directory_contents = listdir(getcwd())
for item in directory_contents:
if item.endswith(".md"):
print(item)
output_name = 'epub/' + item[:-3] + '.epub'
doc = pandoc.read(file=item, format='Markdown')
pandoc.write(doc=doc, file=output_name)
Run the script to export all .md files in the directory as .epub:
python3 export.py
Output directory contents look roughly like below:
.
├── venv
├── elmasri_database_ch_01.md
├── elmasri_database_ch_02.md
├── elmasri_database_ch_03.md
├── elmasri_database_ch_04.md
├── elmasri_database_ch_05.md
├── elmasri_database_ch_06.md
├── elmasri_database_ch_07.md
├── elmasri_database_ch_08.md
├── elmasri_database_ch_09.md
├── elmasri_database_ch_14.md
├── elmasri_database_ch_15.md
├── elmasri_database_ch_16.md
├── elmasri_database_ch_17.md
├── epub
│ ├── elmasri_database_ch_01.epub
│ ├── elmasri_database_ch_02.epub
│ ├── elmasri_database_ch_03.epub
│ ├── elmasri_database_ch_04.epub
│ ├── elmasri_database_ch_05.epub
│ ├── elmasri_database_ch_06.epub
│ ├── elmasri_database_ch_07.epub
│ ├── elmasri_database_ch_08.epub
│ ├── elmasri_database_ch_09.epub
│ ├── elmasri_database_ch_14.epub
│ ├── elmasri_database_ch_15.epub
│ ├── elmasri_database_ch_16.epub
│ └── elmasri_database_ch_17.epub
├── export.py
└── requirements.txt
Read on an E-Reader
Now I have some easy to read files that I can take with me on the bus. I use a Kobo Libra E-Reader, which has nice buttons for paging through and supports pretty much all the open-source file standards you could want. My notes now look pretty nice; even the math symbols show up correctly, albeit a little small.

Obviously, most work in software or in a CS school program can’t be done behind an E-Reader, but there is still a lot of reading involved and, maybe more importantly, only so much time that humans can, and should spend in front a computer screen. This flow helps me to use my commute and other times where I just can’t or don’t want to be at a computer to get some additional learning in.